
Serializability
Serializability Database Transactions Draft
Introduction
- Please read the weak isolation level to understand the need of serializability.
- Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency.
- In other words, the database prevents all possible race conditions.
But if serializable isolation is so much better than the mess of weak isolation levels, then why isn’t everyone using it? To answer this question, we need to look at the options for implementing serializability, and how they perform. There are three main approaches to implementing serializability:
- Acutal Serial Execution - Literally executing transactions in a serial order
- Two-phase locking
- Serializable snapshot isolation
Actual Serial Execution
-
The simplest way of avoiding concurrency problems is to remove the concurrency entirely: to execute only one transaction at a time, in serial order, on a single thread.
-
But how can we achieve this or is this even feasible in a real-world scenario?
-
Two developments caused this rethink
- RAM became cheap enough to allow keeping active datasets in memory for many use cases. This speeds up transactions by eliminating disk I/O delays.
- Database designers recognized that OLTP transactions are typically short and involve few reads/writes, while long-running analytic queries are read-only. This led to the separation of these operations, with analytics running on consistent snapshots (using snapshot isolation) outside of the serial execution loop.
-
The approach of executing transactions serially is implemented in VoltDB/H-Store, Redis, and Datomic
A system designed for single-threaded execution can sometimes perform better than a system that supports concurrency, because it can avoid the coordination overhead of locking. However, its throughput is limited to that of a single CPU core. In order to make the most of that single thread, transactions need to be structured differently from their traditional form.
Encapsulating transactions in stored procedures
You might think booking a flight is one big, seamless operation in a database. Early database designers thought so too! But, it turns out humans are slow decision-makers. Imagine a database holding onto all the information for your flight booking while you ponder options! That would be a huge waste of resources.
- For this reason, systems with single-threaded serial transaction processing don’t allow interactive multi-statement transactions.
- Instead, the application must submit the entire transaction code to the database ahead of time, as a stored procedure.
- The differences between these approaches is shown in the figure. Provided that all data required by a transaction is in memory, the stored procedure can execute very fast, without waiting for any network or disk I/O.
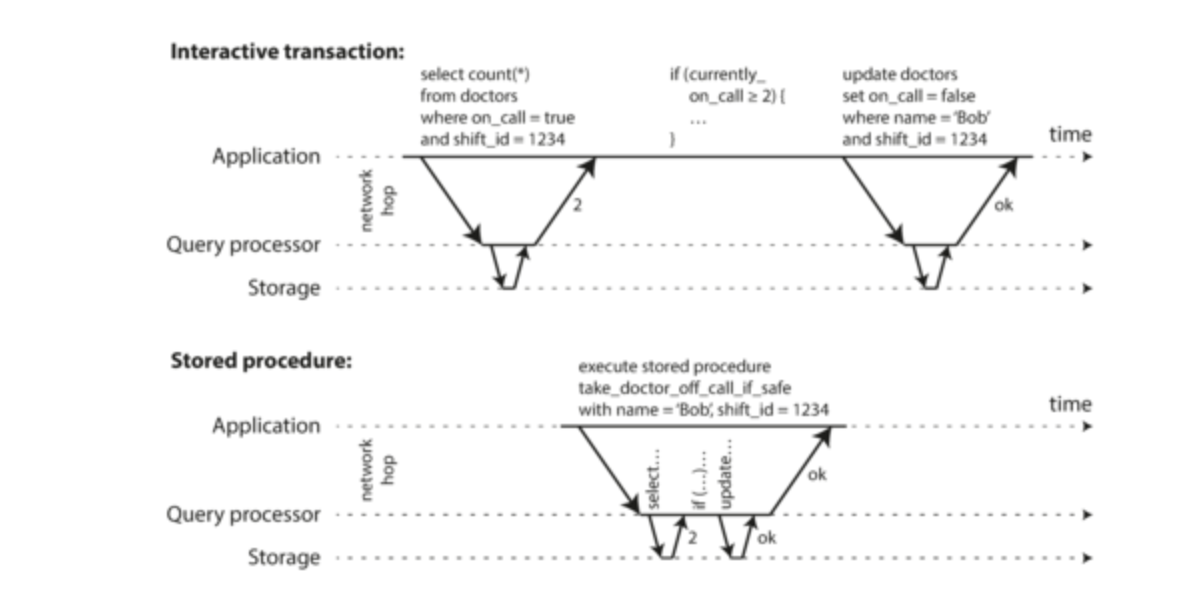
Pros and cons of stored procedures
Stored procedures have gained a somewhat bad reputation, for various reasons:
- Each database vendor has its own language for stored procedures (Oracle has PL/SQL, SQL Server has T-SQL, PostgreSQL has PL/pgSQL, etc.). These languages haven’t kept up with developments in general-purpose programming languages.
- Code running in a database is difficult to manage: compared to an application server, it’s harder to debug, more awkward to keep in version control and deploy.
- A badly written stored procedure (e.g., using a lot of memory or CPU time) in a database can cause much more trouble than equivalent badly written code in an application server.”
However, these issues can be overcome
- Modern implementations of stored procedures have abandoned PL/SQL and use existing general-purpose programming languages instead: VoltDB uses Java or Groovy, Datomic uses Java or Clojure, and Redis uses Lua.
- With stored procedures and in-memory data, executing all transactions on a single thread becomes feasible. As they don’t need to wait for I/O and they avoid the overhead of other concurrency control mechanisms, they can achieve quite good throughput on a single thread.
- VoltDB also uses stored procedures for replication: instead of copying a transaction’s writes from one node to another, it executes the same stored procedure on each replica.
Partitioning
- Executing all transactions serially makes concurrency control much simpler, but limits the transaction throughput of the database to the speed of a single CPU core on a single machine.
- Read-only transactions may execute elsewhere, using snapshot isolation, but for applications with high write throughput, the single-threaded transaction processor can become a serious bottleneck.
- In order to scale to multiple CPU cores, and multiple nodes, you can potentially partition your data
which is supported in VoltDB.
- If you can find a way of partitioning your dataset so that each transaction only needs to read and write data within a single partition, then each partition can have its own transaction processing thread running independently from the others.
- In this case, you can give each CPU core its own partition, which allows your transaction throughput to scale linearly with the number of CPU cores.