
Weak Isolation Levels
Snaphshot Isolation Database Transactions
Introduction
- Serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially (i.e., one at a time, without any concurrency).”
- In practice, isolation is unfortunately not that simple. Serializable isolation has a performance cost, and many databases don’t want to pay that price.
- It’s therefore common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all.
- In this section we will look at several weak (nonserializable) isolation levels that are used in practice, and discuss in detail what kinds of race conditions can and cannot occur, so that you can decide what level is appropriate to your application.
Read Committed
- The most basic level of transaction isolation is read committed.
- It makes two guarantees:
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
No dirty reads
- Imagine a transaction has written some data to the database, but the transaction has not yet committed or aborted.
- Can another transaction see that uncommitted data? If yes, that is called a dirty read.
- Transactions running at the read committed isolation level must prevent dirty reads. This means that any writes by a transaction only become visible to others when that transaction commits (and then all of its writes become visible at once).
No dirty writes
- What happens if two transactions concurrently try to update the same object in a database?
- We don’t know in which order the writes will happen, but we normally assume that the later write overwrites the earlier write.
- However, what happens if the earlier write is part of a transaction that has not yet committed, so the later write overwrites an uncommitted value? This is called a dirty write.
- Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
However, read committed does not prevent the race condition
Implementing read committed
- Most commonly, databases prevent dirty writes by using row-level locks.
- When a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object.
- It must then hold that lock until the transaction is committed or aborted.
- If another transaction wants to write to the same object, it must wait until the first transaction is committed or aborted before it can acquire the lock and continue.
How do we prevent dirty reads?
-
One option would be to use the same lock, and to require any transaction that wants to read an object to briefly acquire the lock and then release it again immediately after reading.
-
However, the approach of requiring read locks does not work well in practice, because one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed.
-
For that reason, most databases prevent dirty reads: for every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock.
-
While the transaction is ongoing, any other transactions that read the object are simply given the old value.
-
Only when the new value is committed do transactions switch over to reading the new value.
Snapshot Isolation and Repeatable Read
-
There are still plenty of ways in which you can have concurrency bugs when using the weak isolation level.
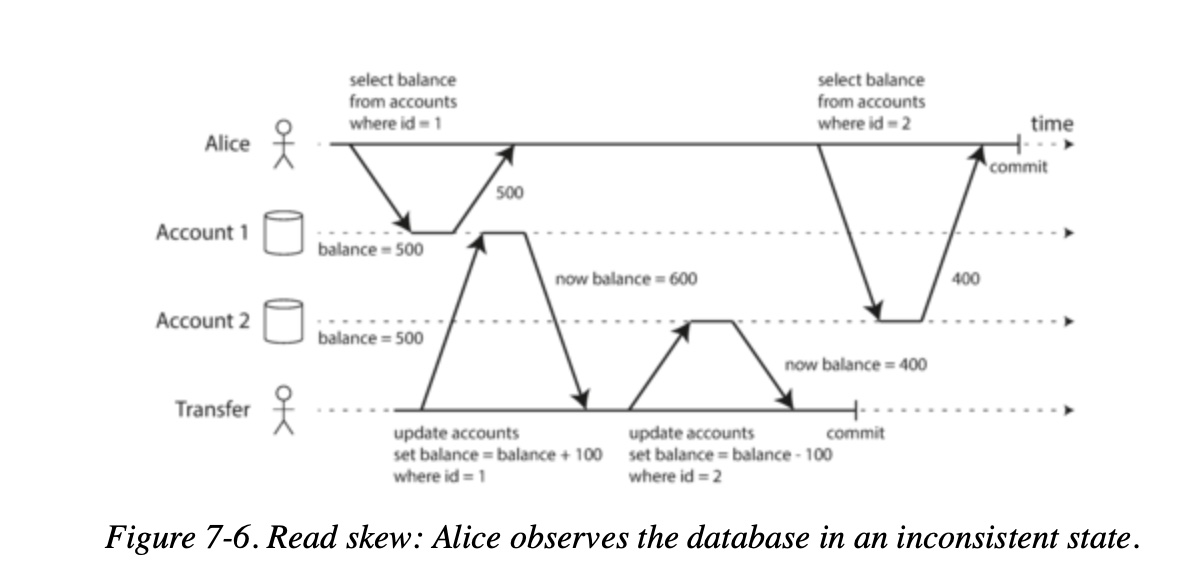
-
Say Alice has $1,000 of savings at a bank, split across two accounts with $500 each.
-
Now a transaction transfers $100 from one of her accounts to the other.
-
If she is unlucky enough to look at her list of account balances in the same moment as that transaction is being processed, she may see one account balance at a time before the incoming payment has arrived (with a balance of $500), and the other account after the outgoing transfer has been made (the new balance being $400).
-
To Alice it now appears as though she only has a total of $900 in her accounts—it seems that $100 has vanished into thin air.
-
This anomaly is called a nonrepeatable read or read skew. In Alice’s case, this is not a lasting problem, because she will most likely see consistent account balances if she reloads the online banking website a few seconds later.
-
However, some situations cannot tolerate such temporary inconsistency:”
-
Backups
- Taking a backup requires making a copy of the entire database, which may take hours on a large database.
- Thus, you could end up with some parts of the backup containing an older version of the data, and other parts containing a newer version.
- If you need to restore from such a backup, the inconsistencies (such as disappearing money) become permanent.
-
Analytic queries and integrity checks
- Sometimes, you may want to run a query that scans over large parts of the database.
- These queries are likely to return nonsensical results if they observe parts of the database at different points in time.
-
-
Snapshot isolation is the most common solution to this problem.
- The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction. - Even if the data is subsequently changed by another transaction, each transaction sees only the old data from that particular point in time.
Implementing snapshot isolation
- Implementations of snapshot isolation typically use write locks to prevent dirty writes, which means - A key principle of snapshot isolation is readers never block writers, and writers never block readers.
- To implement snapshot isolation, databases use a generalization of the mechanism we saw for preventing dirty reads.
- The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time.
- Because it maintains several versions of an object side by side, this technique is known as multi-version concurrency control (MVCC).
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object.
MVCC - Multi-Version Concurrency Control
- When a transaction is started, it is given a unique, always-increasing transaction ID (txid).
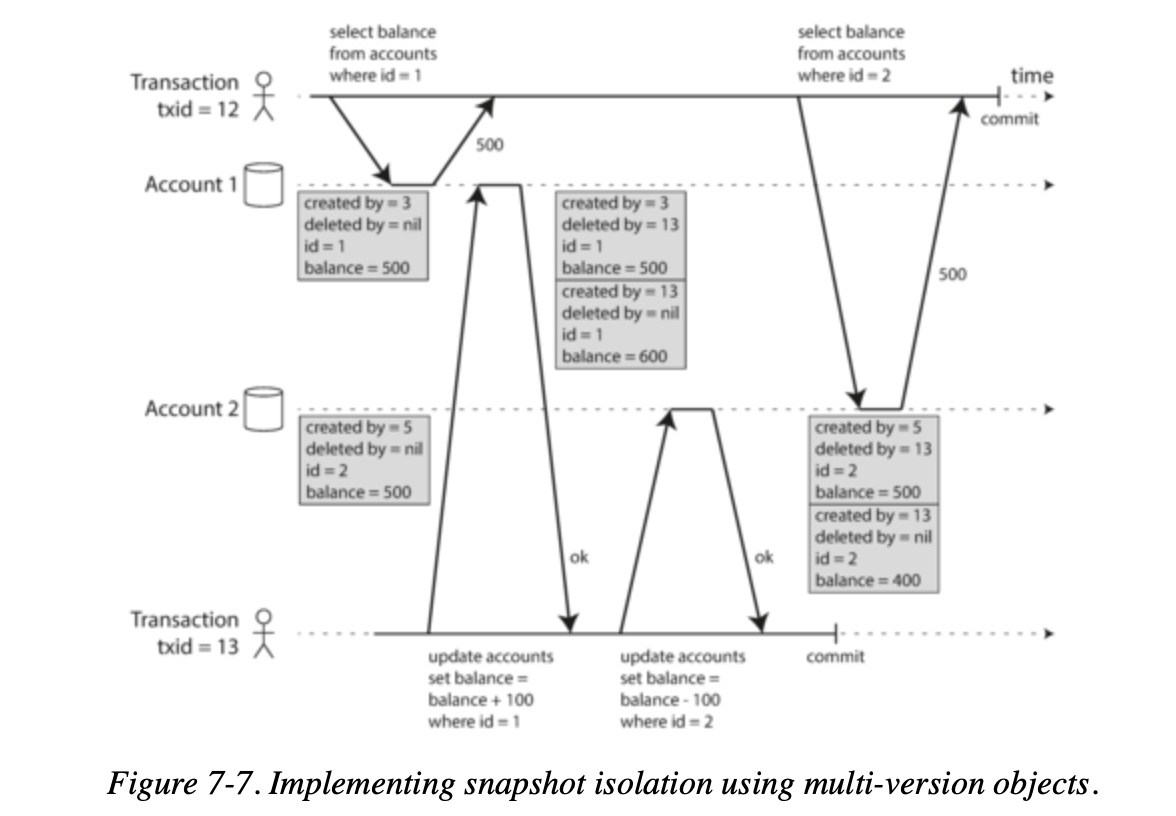
- Each row in a table has a created_by field, containing the ID of the transaction that inserted this row into the table.
- Moreover, each row has a deleted_by field, which is initially empty.
- If a transaction deletes a row, the row isn’t actually deleted from the database, but it is marked for deletion by setting the deleted_by field to the ID of the transaction that requested the deletion.
- At some later time, when it is certain that no transaction can any longer access the deleted data, a garbage collection process in the database removes any rows marked for deletion and frees their space.
- An update is internally translated into a delete and a create.
Visibility rules for observing a consistent snapshot
- When a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible.
- This works as follows:
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time.
- Any writes that those transactions have made are ignored, even if the transactions subsequently commit.
- Any writes made by aborted transactions are ignored.
- Any writes made by transactions with a later transaction ID (i.e., which started after the current transaction started) are ignored, regardless of whether those transactions have committed.
- At the start of each transaction, the database makes a list of all the other transactions that are in progress (not yet committed or aborted) at that time.
- All other writes are visible to the application’s queries.
Preventing Lost Updates
- There are several other interesting kinds of conflicts that can occur between concurrently writing transactions.
- The best known of these is the lost update problem
- The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle). If two transactions do this concurrently, one of the modifications can be lost, because the second write does not include the first modification.
- This pattern occurs in various different scenarios:
- Incrementing a counter or updating an account balance (requires reading the current value, calculating the new value, and writing back the updated value)
- Making a local change to a complex value, e.g., adding an element to a list within a JSON document (requires parsing the document, making the change, and writing back the modified document)
- Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page contents to the server, overwriting whatever is currently in the database.
Avoiding lost updates
- Atomic write operations:- Many databases provide atomic update operations, which remove the need to implement
UPDATE counters SET value = value + 1 WHERE key = 'foo' - Explicit locking:- Another option for preventing lost updates, if the database’s built-in atomic operations don’t provide the necessary functionality, is for the application to explicitly lock objects that are going to be updated.
- Then the application can perform a read-modify-write cycle, and if any other transaction tries to concurrently read the same object, it is forced to wait until the first read-modify-write cycle has completed.
- Automatically detecting lost updates:- An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
- Compare-and-set:- The purpose of this operation is to avoid lost updates by allowing an update to happen only if the value has not changed since you last read it. If the current value does not match what you previously read, the update has no effect, and the read-modify-write cycle must be retried.
Write Skew and Phantoms
-
To begin, imagine this example:
- The hospital usually tries to have several doctors on call at any one time, but it absolutely must have at least one doctor on call.
- Doctors can give up their shifts (e.g., if they are sick themselves), provided that at least one colleague remains on call in that shift
- Now imagine that Alice and Bob are the two on-call doctors for a particular shift.
- Both are feeling unwell, so they both decide to request leave.
- Unfortunately, they happen to click the button to go
- In each transaction, your application first checks that two or more doctors are currently on call; if yes, it assumes it’s safe for one doctor to go off call.
- Since the database is using snapshot isolation, both checks return 2, so both transactions proceed to the next stage.
- Alice updates her own record to take herself off call, and Bob updates his own record likewise.
- Both transactions commit, and now no doctor is on call.
-
This anomaly is called a write skew.
Phantoms causing write skew
Write skew follow a similar pattern:
-
A SELECT query checks whether some requirement is satisfied by searching for rows that match some search condition (there are at least two doctors on call)
-
Depending on the result of the first query, the application code decides how to continue (perhaps to go ahead with the operation, or perhaps to report an error to the user and abort).
-
If the application decides to go ahead, it makes a write (INSERT, UPDATE, or DELETE) to the database and commits the transaction.
-
The effect of this write changes the precondition of the decision of step 2.
-
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom