Redlock - Distributed Lock Manager
redlock locking dlm
- Original Post at : https://redis.io/docs/latest/develop/clients/patterns/distributed-locks/
- Counter that Redlock is not the correct implementation to ensure correctness - https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
Introduction
Distributed locks are a very useful primitive in many environments where different processes must operate with shared resources in a mutually exclusive way.
Minimum Guarantee for Success of Distributed Locks
- Safety: At any point in time, only one process can hold the lock for a given resource.
- Liveness: The lock must be released automatically even when the process holding it fails to release it due to a crash or network failure. This prevents deadlocks.
- Fault Tolerance: As long as the majority of Redis nodes are up, clients are able to acquire and release locks.
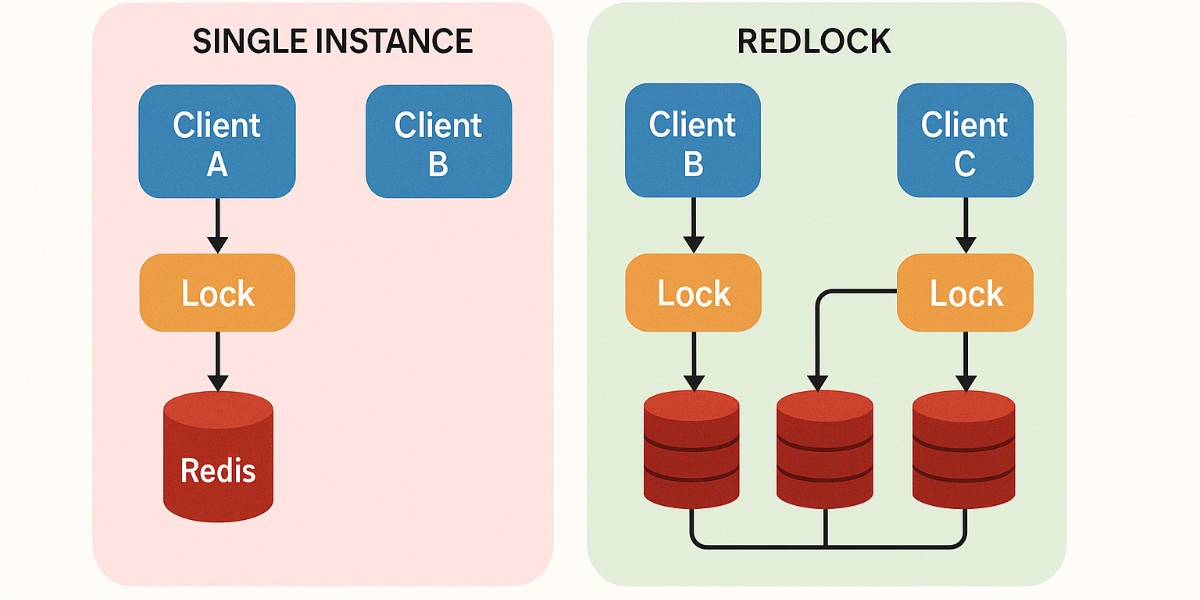
Why normal implementation(single instance) is not enough, or Why Redlock is better
The simplest way to use Redis to lock a resource is to create a key in an instance. The key is usually created with a limited time to live, using the Redis expires feature, so that eventually it will get released. When the client needs to release the resource, it deletes the key.
Superficially this works well, but there is a problem: this is a single point of failure in our architecture. What happens if the Redis master goes down? Well, let’s add a replica! And use it if the master is unavailable. This is unfortunately not viable. By doing so we can’t implement our safety property of mutual exclusion, because Redis replication is asynchronous. There is a race condition with this model:
- Client A acquires the lock in the master.
- The master crashes before the write to the key is transmitted to the replica.
- The replica gets promoted to master.
- Client B acquires the lock to the same resource A already holds a lock for. SAFETY VIOLATION!
Depending on the specific implementation, it is possible for multiple clients to hold the lock simultaneously in the event of a failure. In such cases, the above approach may still be applicable.
Correct Implementation with Single Instance [Accepting Race Condition]
To acquire the lock, the way to go is the following:
SET resource_name my_random_value NX PX 30000
The command sets a key only if it does not already exist (NX option), with an expiry time of 30,000 milliseconds (PX option). The key’s value is set to a unique identifier, such as "my_random_value". This value must be unique for every client and lock request.
The unique value allows the lock to be released safely by running a script that removes the key only if it exists and its value matches the one we expect.
Without this uniqueness, the following problem could occur:
- Client A acquires the lock.
- The TTL for Client A’s lock expires.
- Client B acquires the lock.
- Client A, unaware that its lock has expired, attempts to release it. Since the value is not validated, it unintentionally releases Client B’s lock.
- Client C acquires the lock, even though Client B is still working on the resource—causing unexpected behavior.
By using a random unique value, only the client that originally acquired the lock can release it, preventing this kind of accidental lock release.
The Redlock Algorithm
In the distributed algorithm, we run N independent Redis masters (no replication/coordination). Example: N=5 on separate machines for independent failure tolerance.
To acquire a lock:
- Record current time in ms.
- Try to set the same key and random value on all N instances sequentially, using a small per-instance timeout (e.g., 5–50 ms if auto-release is 10 s) to avoid delays on down nodes.
- Measure elapsed time since step 1. Lock is acquired only if:
- Locked on majority (≥ N/2 + 1) instances, and
- Elapsed time < lock validity time.
- If acquired, remaining validity = initial validity − elapsed time.
- If acquisition fails, unlock all instances (even those likely not locked).
The algorithm relies on the assumption that while there is no synchronized clock across the processes, the local time in every process updates at approximately at the same rate, with a small margin of error compared to the auto-release time of the lock.
When a client is unable to acquire the lock, it should try again after a random delay in order to try to desynchronize multiple clients trying to acquire the lock for the same resource at the same time (this may result in a split brain condition where nobody wins). Also the faster a client tries to acquire the lock in the majority of Redis instances, the smaller the window for a split brain condition (and the need for a retry), so ideally the client should try to send the SET commands to the N instances at the same time using multiplexing.
Extending the lock
If the client’s work is in small steps, use a shorter lock validity and add an extension mechanism. When the lock nears expiry, the client sends a Lua script to all instances to extend the TTL if the key exists and matches its unique value. The lock is renewed only if extended on a majority of instances before expiry. Limit extension attempts to avoid breaking liveness guarantees.
Double Check if the Redlock Algorithm is Actually Safe
- When a client locks most instances, the keys have the same TTL but are set at slightly different times.The lock is valid for at least:
MIN_VALIDITY = TTL - (T2 - T1) - CLOCK_DRIFT
This is the time all keys are guaranteed to exist together, preventing other clients from locking the majority. Multiple clients can only succeed at the same time if locking took longer than the TTL, which makes the lock invalid.
- Let’s assume we configure Redis without persistence at all. A client acquires the lock in 3 of 5 instances. One of the instances where the client was able to acquire the lock is restarted, at this point there are again 3 instances that we can lock for the same resource, and another client can lock it again, violating the safety property of exclusivity of lock.
- Algorithm safety is retained as long as when an instance restarts after a crash, it no longer participates to any currently active lock.To guarantee this we just need to make an instance, after a crash, unavailable for at least a bit more than the max TTL we use. This is the time needed for all the keys about the locks that existed when the instance crashed to become invalid and be automatically released.